חיפוש סמנטי בספר שולחן ערוך: מסע אל עומק הטקסט באמצעות בינה מלאכותית
מבוא
בעידן הדיגיטלי, היכולת למצוא מידע רלוונטי במהירות ובדיוק הפכה לחיונית יותר מתמיד. אבל מה קורה כשאנחנו רוצים לחפש לא רק מילים מדויקות, אלא גם רעיונות ומושגים? כאן נכנס לתמונה החיפוש הסמנטי - טכנולוגיה מתקדמת המאפשרת לנו לחפש משמעות מעבר למילים הכתובות.
בבלוג זה, נצלול לעולם המרתק של חיפוש סמנטי, ונראה כיצד יישמתי טכנולוגיה זו על אחד הספרים החשובים ביותר בהלכה היהודית - “שולחן ערוך” מאת הרב יוסף קארו.
מהו חיפוש סמנטי?
חיפוש סמנטי הוא טכנולוגיה המאפשרת למחשב להבין את המשמעות והכוונה מאחורי שאילתת החיפוש, ולא רק לחפש התאמה מילולית מדויקת. בניגוד לחיפוש מילים מפתח רגיל, חיפוש סמנטי מסוגל להחזיר תוצאות רלוונטיות גם כאשר השאילתה אינה מכילה את המילים המדויקות הנמצאות בטקסט.
כיצד זה עובד?
1. יצירת ייצוגים מספריים (Embeddings)
השלב הראשון בתהליך היה להפוך את הטקסט למספרים שהמחשב יכול “להבין”. זה נעשה באמצעות טכניקה הנקראת “embeddings”.
כדי להמחיש זאת, נתחיל עם דוגמה פשוטה:
נניח שיש לנו שני משפטים:
- “בשבת אסור לבשל”
- “אין לבשל בשבת”
בשיטה פשוטה של ספירת מילים, היינו יכולים לייצג כל משפט כך:
| בשבת | אסור | לבשל | אין |
|---|---|---|---|
| 1 | 1 | 1 | 0 |
| 1 | 0 | 1 | 1 |
כל מספר מייצג כמה פעמים המילה מופיעה במשפט.
אולם, מודלי שפה מתקדמים, כמו אלה שהשתמשתי בהם בפרויקט, עושים הרבה יותר מזה. הם לוקחים בחשבון את ההקשר של כל מילה במשפט, את היחסים בין המילים, ואפילו ניואנסים של משמעות. התוצאה היא ייצוג מספרי מורכב הרבה יותר, שמשקף את המשמעות העמוקה של הטקסט.
- אחסון במסד נתונים וקטורי: לאחר יצירת הייצוגים המספריים, היה עלי לאחסן אותם באופן שיאפשר חיפוש מהיר ויעיל. לשם כך השתמשתי במסד נתונים וקטורי.
מסד נתונים וקטורי הוא כלי מיוחד שמתוכנן לאחסן ולחפש ביעילות רשימות ארוכות של מספרים (וקטורים). הוא מאפשר לנו לבצע חיפושים מהירים על כמויות גדולות של נתונים מסוג זה.
כדי להבין איך זה עובד, נדמיין מצב פשוט עם שני ממדים בלבד. נניח שיש לנו כמה משפטים, וכל משפט מיוצג על ידי שני מספרים בלבד:
- “בשבת אסור לבשל” - (2, 3)
- “מותר לאכול בשר וחלב בנפרד” - (5, 1)
- “יש להדליק נרות שבת לפני השקיעה” - (1, 4)
- “אין לערבב בשר וחלב” - (6, 2)
אם נצייר את הנקודות האלה על גרף, זה ייראה בערך כך:
y
^
4 | •(3)
3 |•(1)
2 | •(4)
1 | •(2)
+---+---+---+---+---+---> x
1 2 3 4 5 6ניתן לראות שמשפטים עם תוכן דומה (כמו 2 ו-4, שעוסקים בבשר וחלב) נמצאים קרוב יחסית זה לזה, בעוד שמשפטים על נושאים שונים (כמו 1 ו-2) רחוקים יותר.
במציאות, אנחנו משתמשים בהרבה יותר ממדים (לרוב מאות או אלפים) כדי לייצג את המשמעות המלאה של המשפטים. אבל העיקרון נשאר זהה - משפטים דומים במשמעותם יהיו קרובים זה לזה במרחב הרב-ממדי הזה.
מסד הנתונים הווקטורי מאחסן את כל הנקודות האלה ומאפשר לנו למצוא במהירות אילו נקודות קרובות לנקודה מסוימת. זה בדיוק מה שאנחנו צריכים כדי למצוא משפטים דומים במשמעותם.
- חיפוש מקורב (Approximate Nearest Neighbor - ANN): החלק האחרון של המערכת הוא אלגוריתם החיפוש עצמו. כאן השתמשתי בטכניקה הנקראת “חיפוש מקורב” או ANN (Approximate Nearest Neighbor).
כיצד ANN עובד?
ANN מבוסס על רעיון פשוט אך חכם: במקום לבדוק כל וקטור במסד הנתונים (מה שיכול להיות איטי מאוד), הוא מקבץ וקטורים דומים לקבוצות ואז מחפש רק בקבוצות הרלוונטיות ביותר.
הנה הצעדים העיקריים:
-
קיבוץ לקבוצות:
- המרחב הווקטורי מחולק ל”שכונות” או קבוצות.
- וקטורים דומים נמצאים באותה קבוצה או בקבוצות סמוכות.
-
בניית אינדקס:
- נבנה מבנה נתונים מיוחד (אינדקס) שמאפשר לזהות במהירות לאיזו קבוצה שייך כל וקטור.
-
חיפוש מהיר:
- כשמגיעה שאילתת חיפוש, האלגוריתם מזהה את הקבוצה או הקבוצות הרלוונטיות.
- הוא מחפש רק בתוך הקבוצות האלה, במקום לסרוק את כל מסד הנתונים.
המחשה פשוטה
נדמיין שיש לנו ספרייה ענקית עם מיליוני ספרים. במקום לחפש בכל מדף, הספרים מסודרים לפי נושאים (הקבוצות שלנו). כשאנחנו מחפשים ספר על היסטוריה, אנחנו הולכים ישר למדפי ההיסטוריה ומחפשים שם, במקום לעבור על כל הספרייה.
היתרון במהירות
החיפוש הזה הרבה יותר מהיר מחיפוש ממצה, במיוחד כשיש לנו כמויות עצומות של נתונים. במקום לבדוק מיליוני וקטורים, אנחנו בודקים רק אלפים או אפילו מאות.
המחיר בדיוק
אבל יש מחיר קטן לשלם עבור המהירות הזו. יש סיכוי קטן שנפספס כמה תוצאות רלוונטיות שנמצאות בקבוצות אחרות. זה כמו שאולי נפספס ספר היסטוריה שבטעות הונח במדף של מדע בדיוני.
בפועל, הירידה בדיוק היא לרוב קטנה מאוד, והיתרון במהירות הוא עצום. זה מאפשר לנו לחפש במהירות בתוך כמויות עצומות של מידע, מה שהופך את החיפוש הסמנטי למעשי ויעיל.
יישום על ספר “שולחן ערוך”
בפרויקט זה, יישמתי את טכנולוגיית החיפוש הסמנטי על ספר “שולחן ערוך”, אחד החיבורים החשובים ביותר בהלכה היהודית. הנה כמה נקודות מעניינות מהתהליך:
-
עיבוד הטקסט:
- חילקתי את הספר לקטעים קצרים, כל אחד מייצג סעיף - קטע הלכתי ספציפי.
- כל קטע עבר עיבוד על ידי מודל שפה מתקדם ליצירת הווקטור שלו.
-
יצירת מסד נתונים:
- כל הווקטורים אוחסנו במסד נתונים וקטורי, המאפשר חיפוש מהיר ויעיל.
-
ממשק חיפוש:
- פיתחתי ממשק המאפשר למשתמשים להזין שאלות או נושאים בשפה טבעית.
- המערכת מחזירה את ההלכות הרלוונטיות ביותר מתוך הספר.
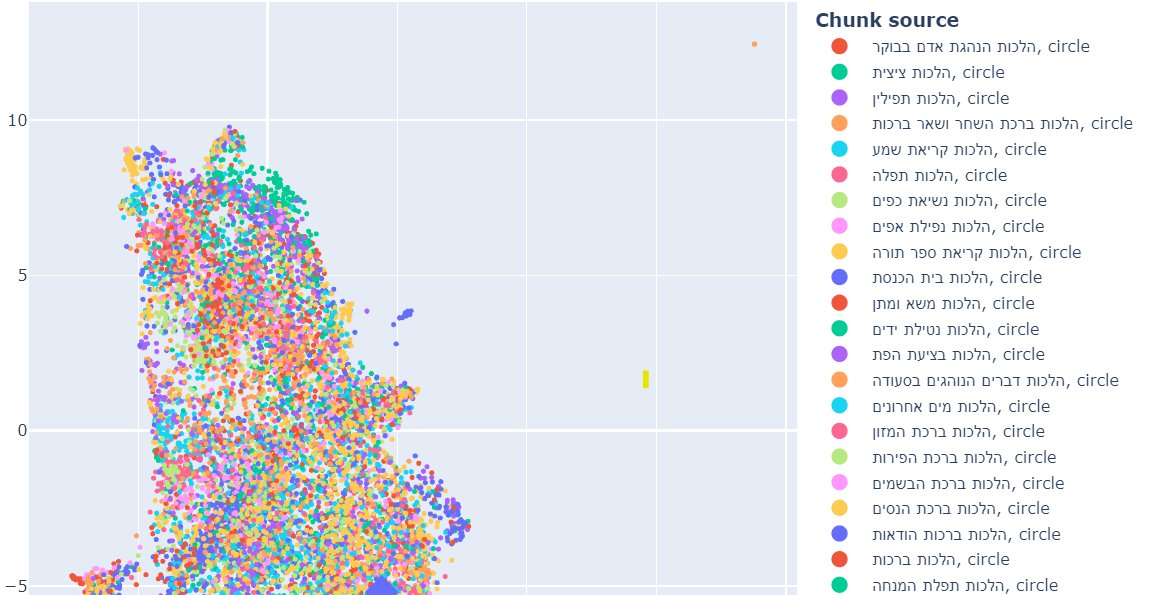
הדגמה ויזואלית
אחד החלקים המרתקים בפרויקט היה יצירת הדגמה דו-ממדית של מסד הנתונים. בהדגמה זו, ניתן לראות כיצד:
- נושאים דומים נמצאים בקרבת מקום זה לזה במרחב הווקטורי.
- נושאים שונים ממוקמים במרחק זה מזה.
הדגמה זו ממחישה את העוצמה של הייצוג הווקטורי - היכולת לתפוס ולייצג מושגים מופשטים במרחב מתמטי. מומלץ לשחק בהמחשה הויזואלית ולהבחין במיקומים השונים של הטקסטים בהתאם לנושא בו הם עוסקים.
קישור להמחשה הויזואליתיתרונות ושימושים
- חיפוש מדויק יותר: משתמשים יכולים למצוא מידע רלוונטי גם אם אינם יודעים את המונחים המדויקים.
- הבנת הקשר: המערכת מסוגלת להבין הקשרים ולהציע תוצאות קשורות.
- גילוי ידע: אפשרות לגלות קשרים וחיבורים שלא היו ברורים קודם לכן בין חלקים שונים של הטקסט.
סיכום
חיפוש סמנטי מייצג צעד משמעותי קדימה בתחום אחזור המידע. ביישום הטכנולוגיה על ספר “שולחן ערוך”, הצלחנו להפוך טקסט עתיק ומורכב לנגיש וחיפוש יותר מאי פעם. זוהי דוגמה מצוינת לכיצד טכנולוגיות מתקדמות יכולות לשפר את הגישה שלנו לידע מסורתי ולהעשיר את הלמידה והמחקר בתחומים מגוונים.
הפרויקט הזה פותח צוהר לאפשרויות רבות נוספות - החל מיישום דומה על טקסטים קלאסיים אחרים, ועד לפיתוח כלים מתקדמים ללימוד והבנה של טקסטים מורכבים. העתיד של למידה ומחקר טקסטואלי נראה מבטיח יותר מתמיד!